GenAI RAG PoC
GenAI RAG with custom embeddings | Proof-of-Concept (PoC)

July 2023
Abstract
How to leverage the currently hyped topic of GenerativeAI to quickly process multi-variant and unnormalised datasets to find specific content? Let’s say, you have a couple of text-based documents like PDFs that you would like to make easier accessible and browsable based on certain intents regarding particular snippets of information you are looking for. Further, you would like to apply a conversational style to this experience where replies to the exact same question might slightly vary to make it feel more natural and human. With the release of various LLMs (Large Language Models) like OpenAI’s GPT-3.5, those requirements become more feasible.
However, using LLMs „in isolation is often insufficient for creating a truly powerful app – the real power comes when you can combine them with other sources of computation or knowledge“1. Depending on the volume of documents/sources you would like to embed in such an application, performance-wise it is worth considering transforming your embeddings into a vector store to enable efficient similarity search to be run with your input in order to gain better contextual results. A good choice for this part in the array of components we will be using, is the FAISS library2 from Meta Research.
Plugging it all together
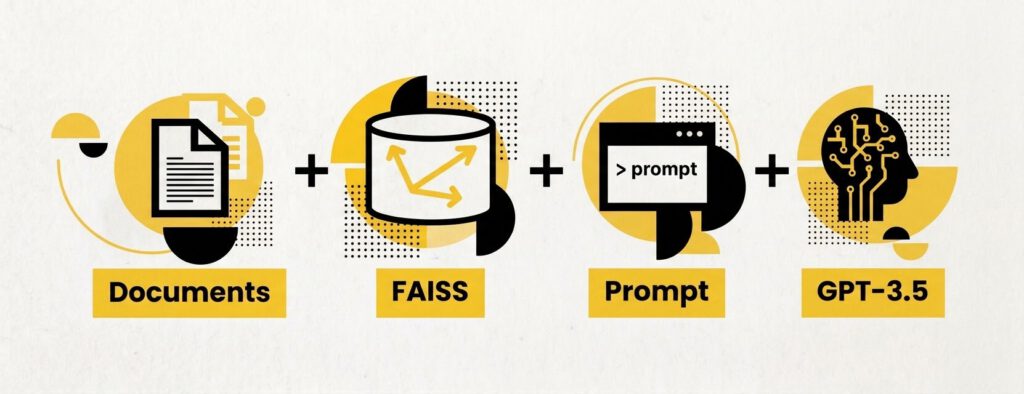
Backend (Python)
Let’s jump straight into the code to highlight some main components of our application – make sure you create your OPENAI_API_KEY beforehand and inject it as an environment variable.
1. Implement parser(s) to handle your documents file format, e.g. .pdf and define the desired chunk size and overlap (the chunk_overlap parameter is used to specify the number of overlapping tokens between consecutive chunks. This is useful when splitting text to maintain context continuity between chunks. By including some overlapping tokens, you can ensure that a small portion of context is shared between adjacent chunks, which can help with preserving the meaning and coherence when processing the text with language models. Try to strike a good balance between size and overlap, e.g {700, 30}):
def split_text(docs, chunk_size, chunk_overlap):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
return text_splitter.split_documents(docs)
###################################################################
def build_pdf_texts(path, subpath, chunk_size, chunk_overlap):
docs = []
files = os.listdir(f"{path}/{subpath}")
files = [doc for doc in files if doc.endswith('.pdf')]
for file in files:
loader = PyMuPDFLoader(f"{path}/{subpath}/{file}")
pages = loader.load()
for page in pages:
docs.append(page)
return split_text(docs, chunk_size, chunk_overlap)
2. Build and load the FAISS vector store from your source documents to be embedded:
def build_vector_store(texts, path, subpath, embeddings):
vectorstore = FAISS.from_documents(texts, embeddings)
vectorstore.save_local(f'{path}/{subpath}/vectorstore')
####################################################################################
def load_vectorstore(source, embeddings):
if not Path(f'{source}/vectorstore').exists():
raise ValueError("Vector store does not exist.")
vectorstore = FAISS.load_local(f'{source}/vectorstore', embeddings)
return vectorstore
3. Define the prompt for your generative text, i.e. the characteristics of the used LLM:
def prompt_config():
system_template = """
You are a representative of `FabFour Inc.`.
It is your job to answer the incoming questions from a fan. Please note:
- Answer the questions exclusively with the information provided after "Sources:".
- If the fan's question cannot be answered by the information listed there, you say `there will be an answer, let it be`.
- Answer in English and in a structured manner.
Sources:
{context}
{chat_history}"""
{question}
Use Markdown format for your answers
"""
messages = [SystemMessagePromptTemplate.from_template(system_template)]
prompt = ChatPromptTemplate.from_messages(messages)
return prompt
4. Initiate the chain with the desired LLM, embeddings, vector store and prompt to be used:
def initiate_chain(source, subpath):
llm = ChatOpenAI(
model_name='gpt-3.5-turbo',
openai_api_key=os.environ['OPENAI_API_KEY']
)
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['OPENAI_API_KEY'])
vectorstore = load_vectorstore(source, subpath, embeddings)
prompt = prompt_config()
return set_chain(llm, vectorstore, prompt)
5. We will be using Flask to simply expose our service through an API endpoint:
qanda_request = api.model('QARequest', {
'question': fields.String(required=True,
description='The fan's question to answer',
example='When did The Beatles record their final studio album?'),
})
qanda_response = api.model('QAResponse',
{
'answer': fields.String,
'sources': fields.List(
fields.Nested(api.model('Source',
{
'file_name': fields.String,
'file_content': fields.String
})
)
)
})
@app.route("/fan-qa", endpoint='fan-qa')
@api.doc(responses={
200: 'Success',
400: 'Bad Request'
})
@api.expect(qanda_request)
@api.marshal_with(qanda_response)
def post(self):
data = request.json
if 'question' not in data:
return {'error': 'No question has been asked'}, 400
try:
response = chain({'question': data['question']})
except Exception as e:
return {'answer': 'There will be an answer, let it be!', 'sources': []}
return parse_response(response)
Demo
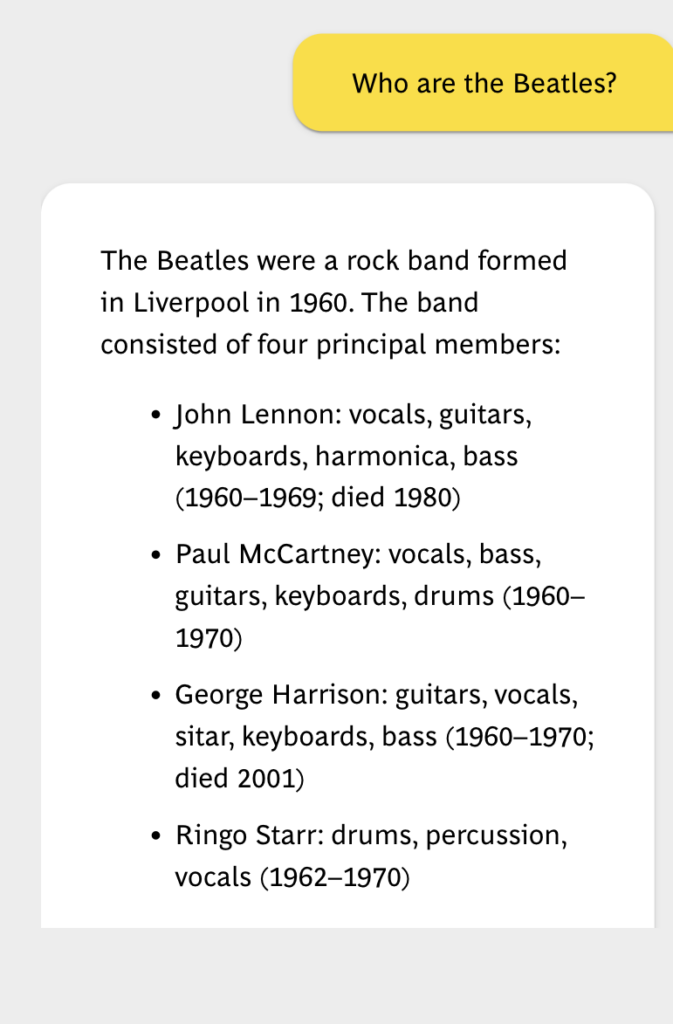
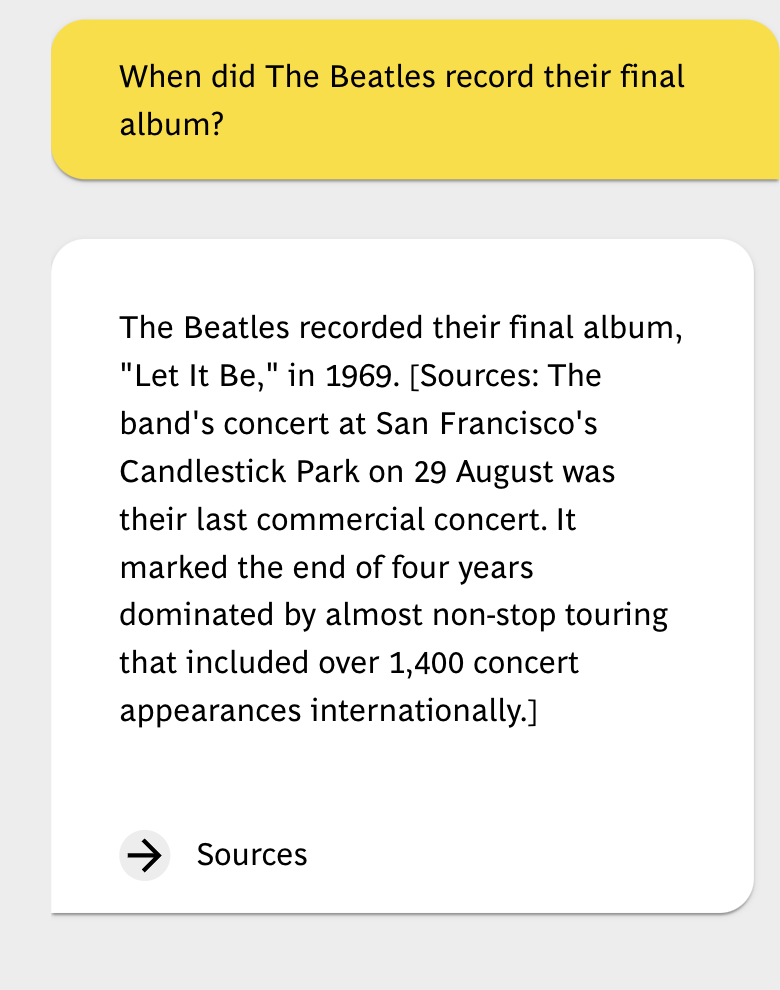
Technologies
-
- Python
- OpenAI API
- GPT-3.5 (natural language model)
- FAISS
- LangChain
- Flask
- Heroku

